Partitioning the variance across factors
John Blischak
2017-09-18
Last updated: 2018-01-29
Code version: f6b7f76
Batch 1 only
Setup
library("cowplot")
library("edgeR")
library("ggplot2")
library("variancePartition")
theme_set(theme_cowplot())
source("../code/functions.R")
library("Biobase") # has to be loaded last to use `combine`Import data.
eset <- readRDS("../data/eset.rds")
esetExpressionSet (storageMode: lockedEnvironment)
assayData: 54792 features, 4992 samples
element names: exprs
protocolData: none
phenoData
sampleNames: 03162017-A01 03162017-A02 ... 12142017-H12 (4992
total)
varLabels: experiment well ... valid_id (40 total)
varMetadata: labelDescription
featureData
featureNames: ENSG00000000003 ENSG00000000005 ... WBGene00235374
(54792 total)
fvarLabels: chr start ... source (6 total)
fvarMetadata: labelDescription
experimentData: use 'experimentData(object)'
Annotation: Limit this analysis to batch 1 since it deals with the spike-ins.
eset <- eset[, eset$batch == "b1"]
dim(eset)Features Samples
54792 960 Remove samples with bad cell number, lack of TRA-1-60 signal, or an invalid individual assignment.
eset_quality <- eset[, eset$cell_number == 1 & eset$tra1.60 & eset$valid_id]
dim(eset_quality)Features Samples
54792 814 Separate by source.
eset_ce <- eset_quality[fData(eset_quality)$source == "C. elegans", ]
head(featureNames(eset_ce))[1] "WBGene00000001" "WBGene00000002" "WBGene00000003" "WBGene00000004"
[5] "WBGene00000005" "WBGene00000006"eset_dm <- eset_quality[fData(eset_quality)$source == "D. melanogaster", ]
head(featureNames(eset_dm))[1] "FBgn0000008" "FBgn0000014" "FBgn0000015" "FBgn0000017" "FBgn0000018"
[6] "FBgn0000022"eset_ercc <- eset_quality[fData(eset_quality)$source == "ERCC",
eset_quality$ERCC != "Not added"]
head(featureNames(eset_ercc))[1] "ERCC-00002" "ERCC-00003" "ERCC-00004" "ERCC-00009" "ERCC-00012"
[6] "ERCC-00013"eset_hs <- eset_quality[fData(eset_quality)$source == "H. sapiens", ]
head(featureNames(eset_hs))[1] "ENSG00000000003" "ENSG00000000005" "ENSG00000000419" "ENSG00000000457"
[5] "ENSG00000000460" "ENSG00000000938"Define a function for partitioning the variance.
# https://bioconductor.org/packages/3.4/bioc/vignettes/variancePartition/inst/doc/variancePartition.R
calc_partition <- function(x, info, cores = 1) {
stopifnot(c("experiment", "chip_id") %in% colnames(info))
library("doParallel")
cl <- makeCluster(cores)
registerDoParallel(cl)
form <- ~ (1|experiment) + (1|chip_id)
varPart <- fitExtractVarPartModel(x, form, info)
vp <- sortCols(varPart)
return(vp)
}ERCC
Remove zeros.
eset_ercc_clean <- eset_ercc[rowSums(exprs(eset_ercc)) != 0, ]
dim(eset_ercc_clean)Features Samples
87 294 Only keep genes which are observed in at least 50% of the samples.
eset_ercc_clean <- eset_ercc_clean[apply(exprs(eset_ercc_clean), 1, present), ]
dim(eset_ercc_clean)Features Samples
31 294 mol_ercc_cpm <- cpm(exprs(eset_ercc_clean), log = TRUE)part_ercc <- calc_partition(mol_ercc_cpm, pData(eset_ercc_clean))Loading required package: iteratorsProjected run time: ~ 0.6 min plotPercentBars(part_ercc)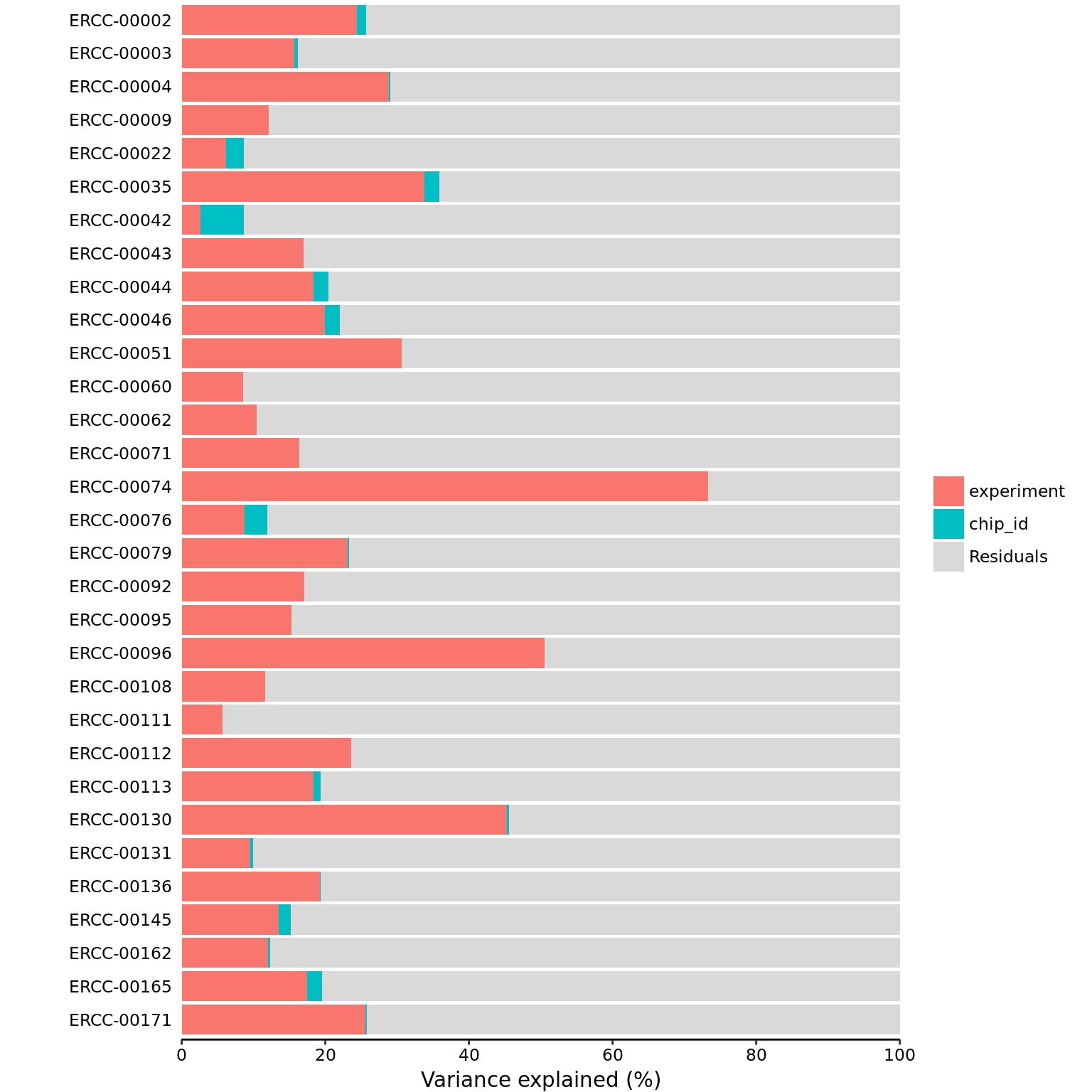
plotVarPart(part_ercc, main = sprintf("ERCC (n = %d)", nrow(part_ercc)))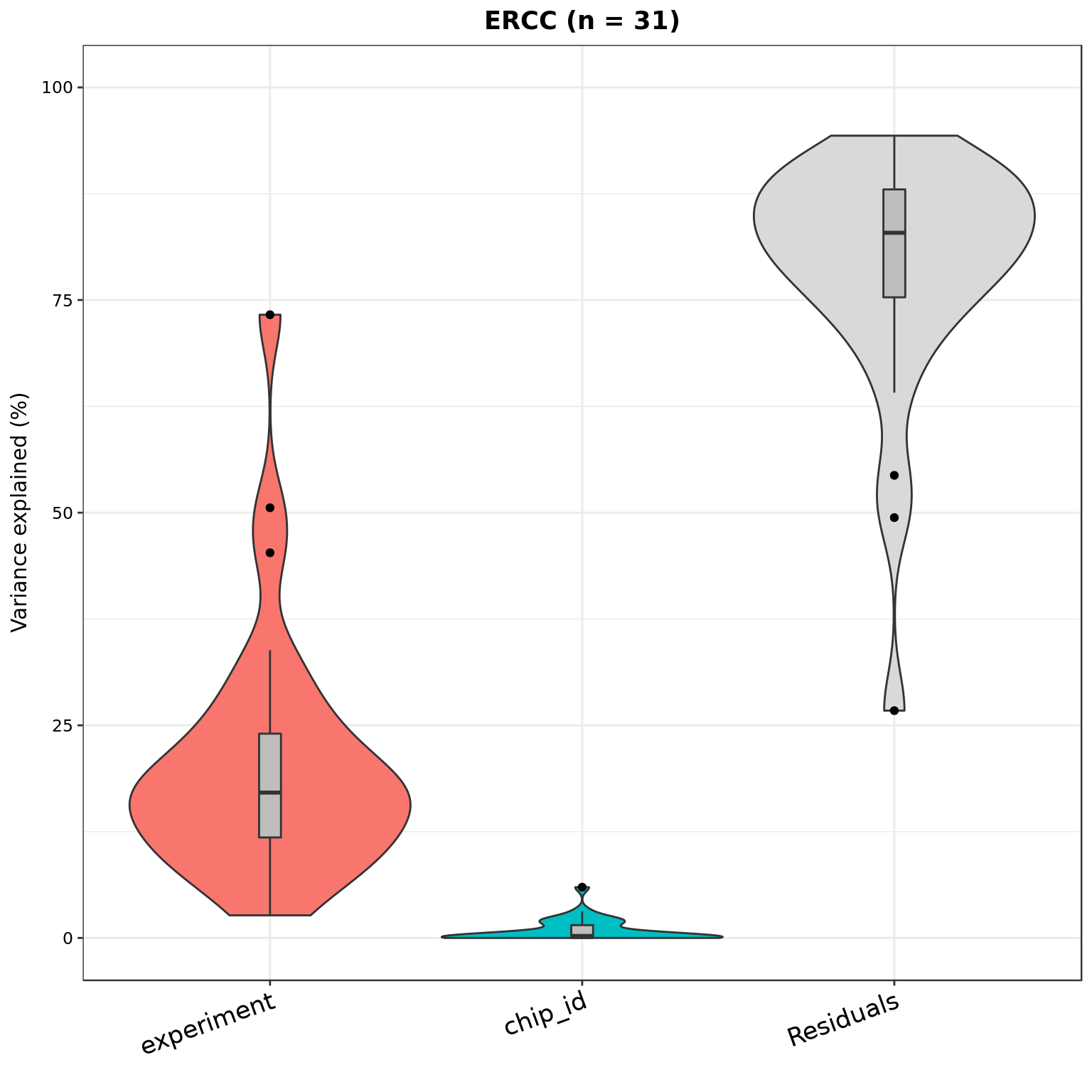
Drosophila
Remove zeros.
eset_dm_clean <- eset_dm[rowSums(exprs(eset_dm)) != 0, ]
dim(eset_dm_clean)Features Samples
11509 814 Only keep genes which are observed in at least 50% of the samples.
eset_dm_clean <- eset_dm_clean[apply(exprs(eset_dm_clean), 1, present), ]
dim(eset_dm_clean)Features Samples
328 814 Convert to log2 counts per million.
mol_dm_cpm <- cpm(exprs(eset_dm_clean), log = TRUE)part_dm <- calc_partition(mol_dm_cpm, pData(eset_dm_clean))Projected run time: ~ 0.7 min plotPercentBars(part_dm)
plotVarPart(part_dm, main = sprintf("Fly (n = %d)", nrow(part_dm)))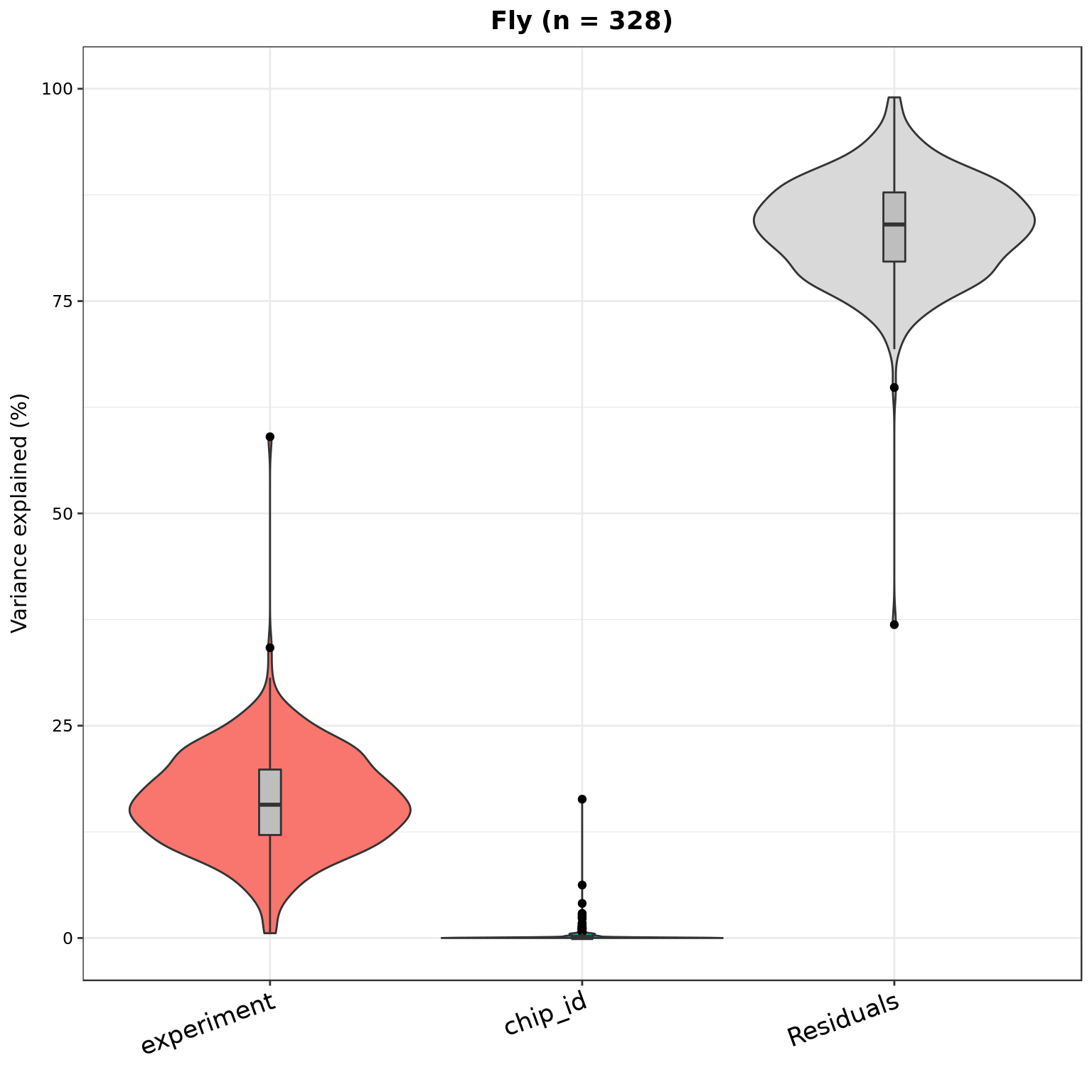
Drosophila - 5 pg
Select only samples that received 5 pg.
eset_dm_5pg <- eset_dm[, eset_dm$fly == 5000]
dim(eset_dm_5pg)Features Samples
13832 325 Remove zeros.
eset_dm_5pg_clean <- eset_dm_5pg[rowSums(exprs(eset_dm_5pg)) != 0, ]
dim(eset_dm_5pg_clean)Features Samples
9786 325 Only keep genes which are observed in at least 50% of the samples.
eset_dm_5pg_clean <- eset_dm_5pg_clean[apply(exprs(eset_dm_5pg_clean), 1, present), ]
dim(eset_dm_5pg_clean)Features Samples
157 325 Convert to log2 counts per million.
mol_dm_5pg_cpm <- cpm(exprs(eset_dm_5pg_clean), log = TRUE)part_dm_5pg <- calc_partition(mol_dm_5pg_cpm, pData(eset_dm_5pg_clean))Projected run time: ~ 0.2 min plotPercentBars(part_dm_5pg)Warning: closing unused connection 7 (<-localhost:11466)Warning: closing unused connection 6 (<-localhost:11466)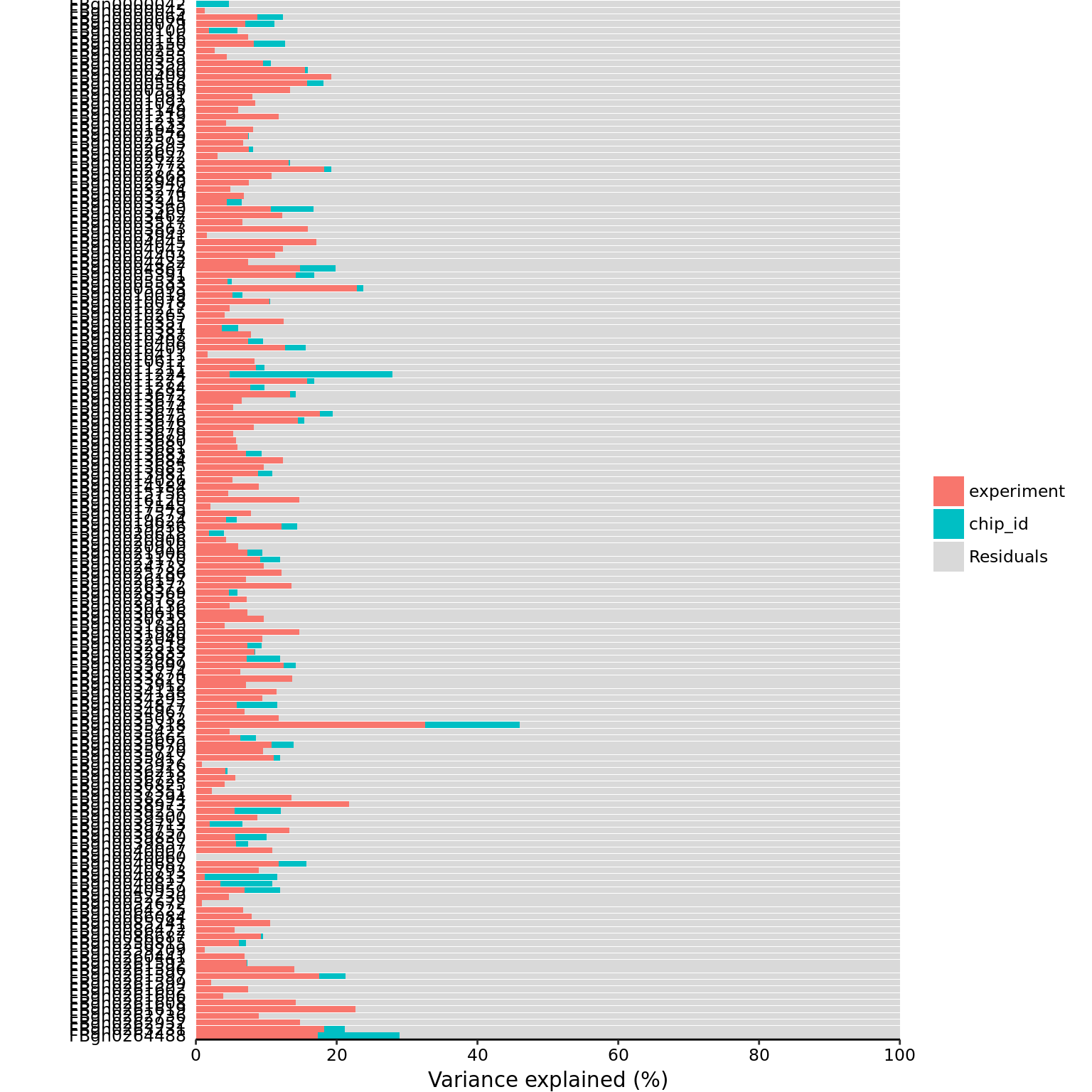
plotVarPart(part_dm_5pg, main = sprintf("Fly (5 pg; n = %d)", nrow(part_dm_5pg)))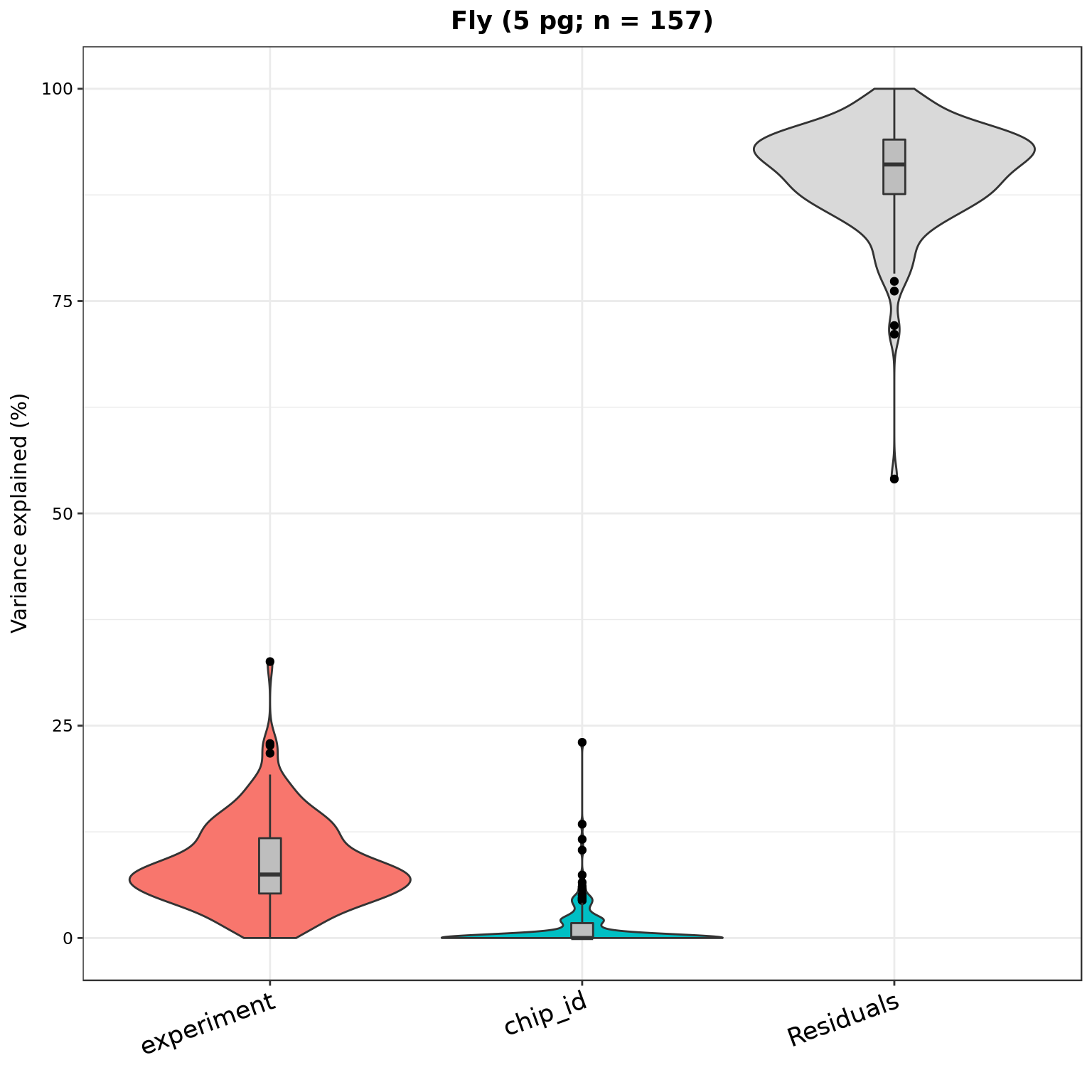
Drosophila - 50 pg
Select only samples that received 50 pg.
eset_dm_50pg <- eset_dm[, eset_dm$fly == 50000]
dim(eset_dm_50pg)Features Samples
13832 489 Remove zeros.
eset_dm_50pg_clean <- eset_dm_50pg[rowSums(exprs(eset_dm_50pg)) != 0, ]
dim(eset_dm_50pg_clean)Features Samples
11038 489 Only keep genes which are observed in at least 50% of the samples.
eset_dm_50pg_clean <- eset_dm_50pg_clean[apply(exprs(eset_dm_50pg_clean), 1, present), ]
dim(eset_dm_50pg_clean)Features Samples
525 489 Convert to log2 counts per million.
mol_dm_50pg_cpm <- cpm(exprs(eset_dm_50pg_clean), log = TRUE)part_dm_50pg <- calc_partition(mol_dm_50pg_cpm, pData(eset_dm_50pg_clean))Projected run time: ~ 0.7 min plotPercentBars(part_dm_50pg)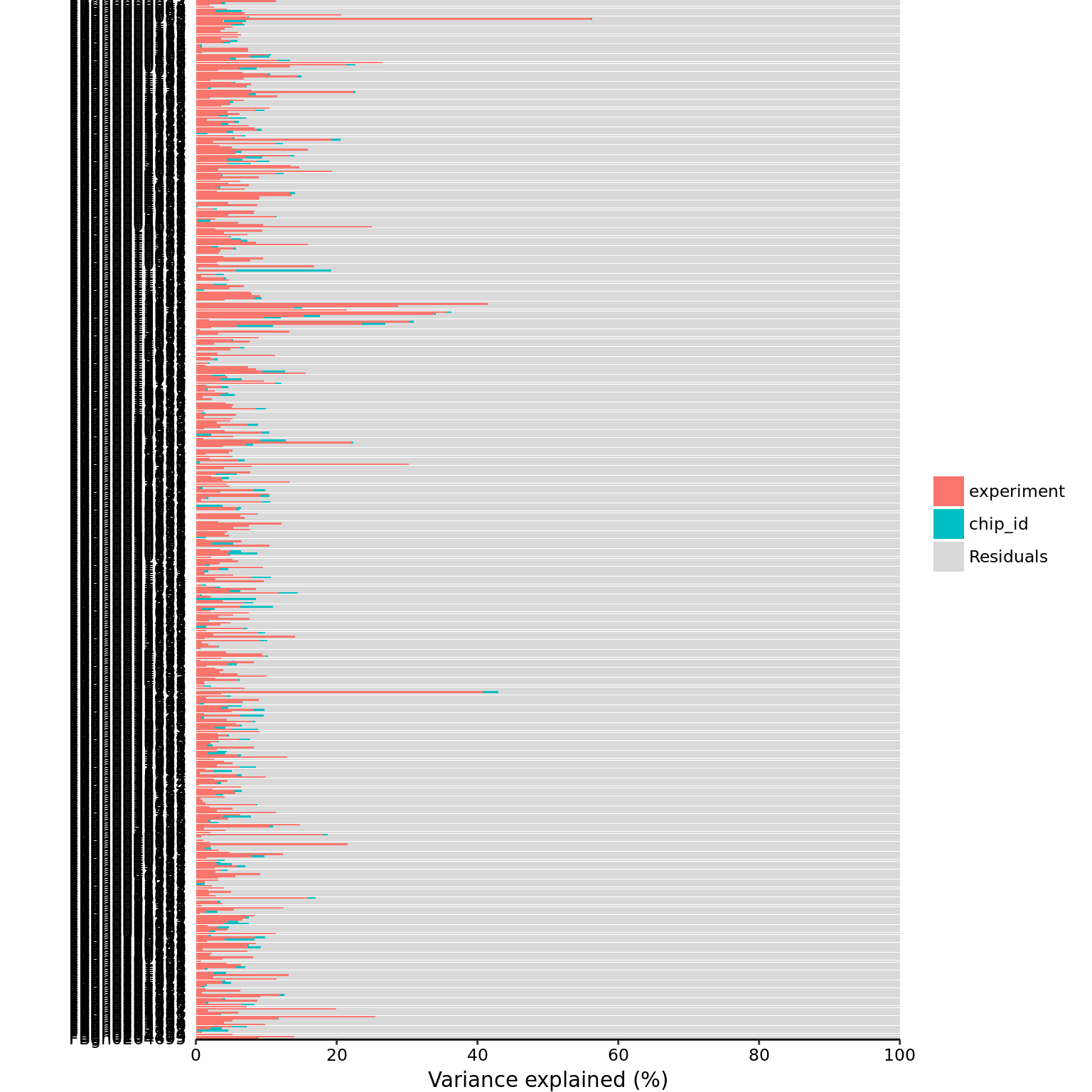
plotVarPart(part_dm_50pg, main = sprintf("Fly (50 pg; n = %d)", nrow(part_dm_50pg)))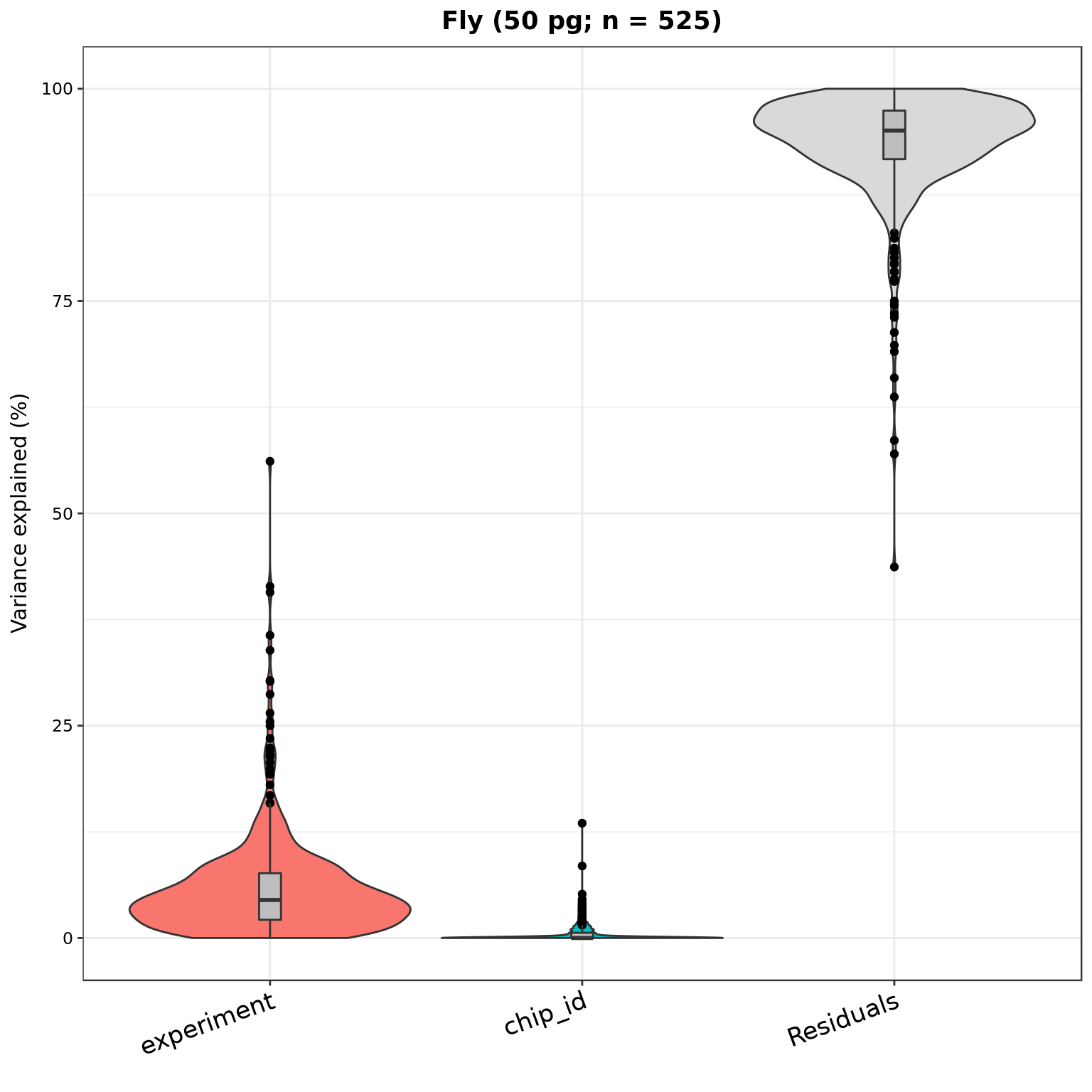
Human
Remove zeros.
eset_hs_clean <- eset_hs[rowSums(exprs(eset_hs)) != 0, ]
dim(eset_hs_clean)Features Samples
18868 814 Only keep genes which are observed in at least 50% of the samples.
eset_hs_clean <- eset_hs_clean[apply(exprs(eset_hs_clean), 1, present), ]
dim(eset_hs_clean)Features Samples
6681 814 This takes too long on the full data set. Subsample the genes to get the idea.
n_genes <- nrow(eset_hs_clean)
eset_hs_clean_sub <- eset_hs_clean[sample(1:n_genes, size = floor(n_genes * 0.05)), ]
dim(eset_hs_clean_sub)Features Samples
334 814 Convert to log2 counts per million.
mol_hs_cpm <- cpm(exprs(eset_hs_clean_sub), log = TRUE)part_hs <- calc_partition(mol_hs_cpm, pData(eset_hs_clean_sub))Projected run time: ~ 0.6 min plotPercentBars(part_hs)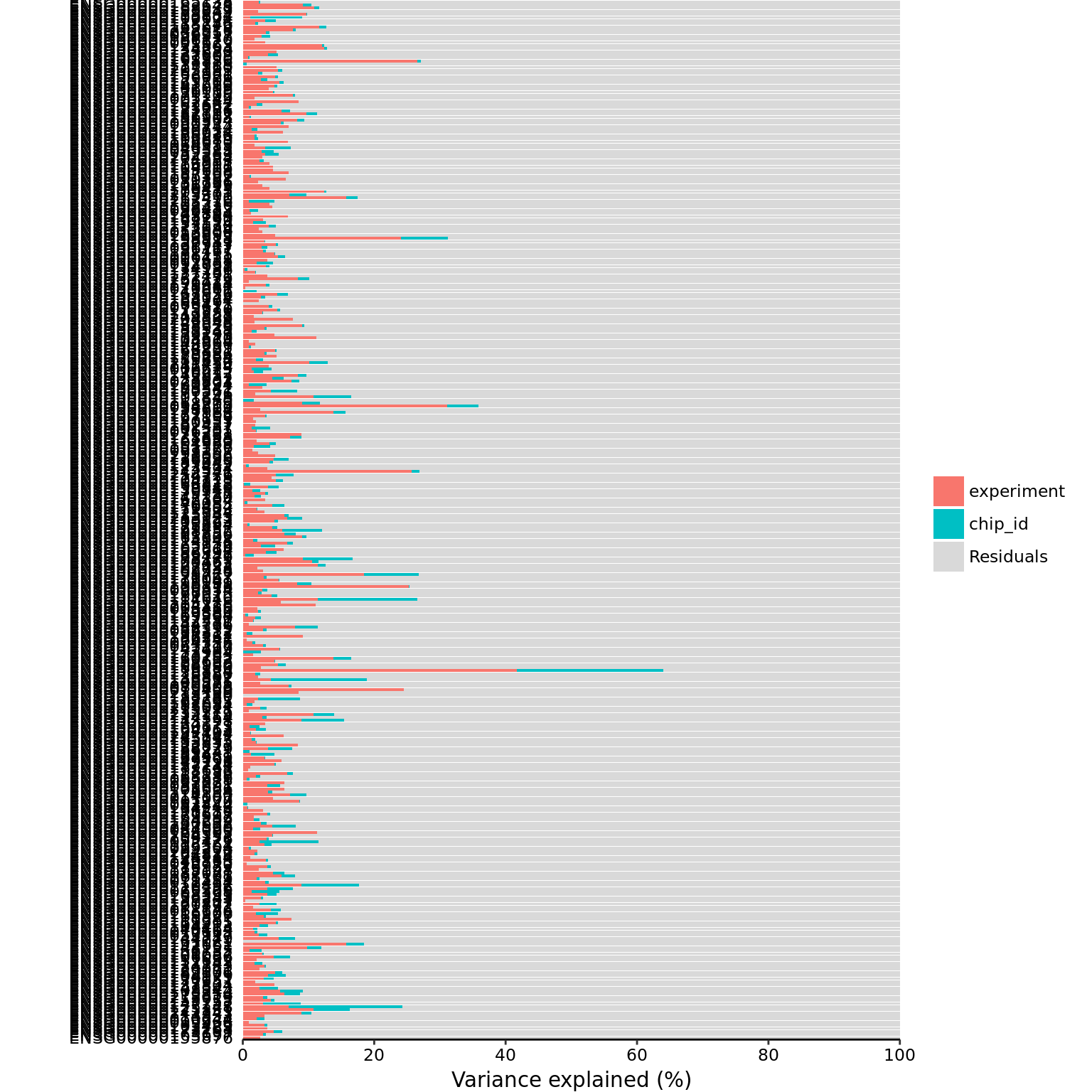
plotVarPart(part_hs, main = sprintf("Human (n = %d)", nrow(part_hs)))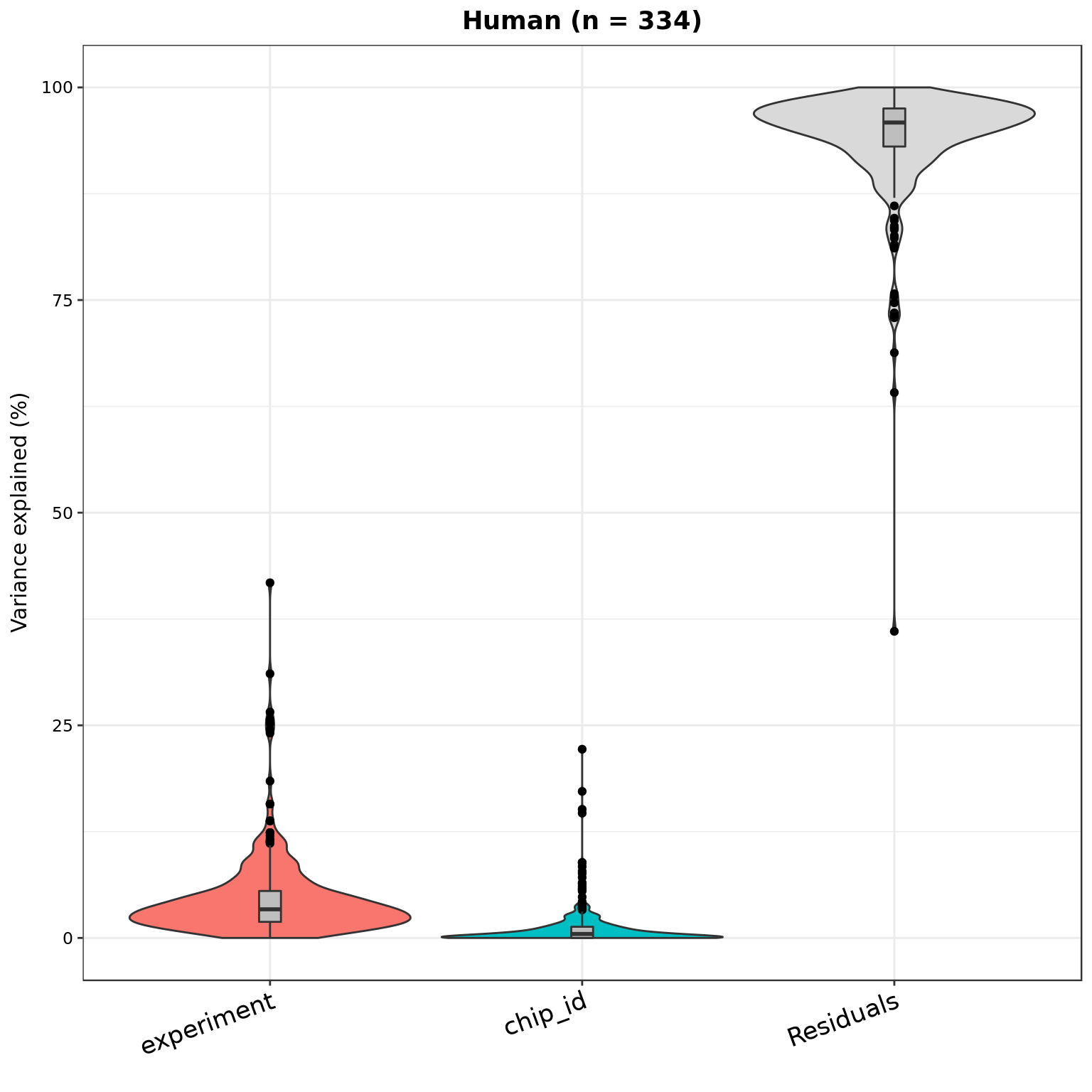
Final plot
x_labels <- scale_x_discrete(labels = c("C1 chip", "Individual", "Residuals"))
x_title <- labs(x = "Model coefficient")
plot_grid(plotVarPart(part_ercc, main = sprintf("ERCC (n = %d)", nrow(part_ercc))) +
x_labels + x_title,
plotVarPart(part_hs, main = sprintf("Human (n = %d)", nrow(part_hs))) +
x_labels + x_title,
labels = LETTERS[1:2])Warning in "factor" %in% attrib[["class", exact = TRUE]]: closing unused
connection 6 (<-localhost:11466)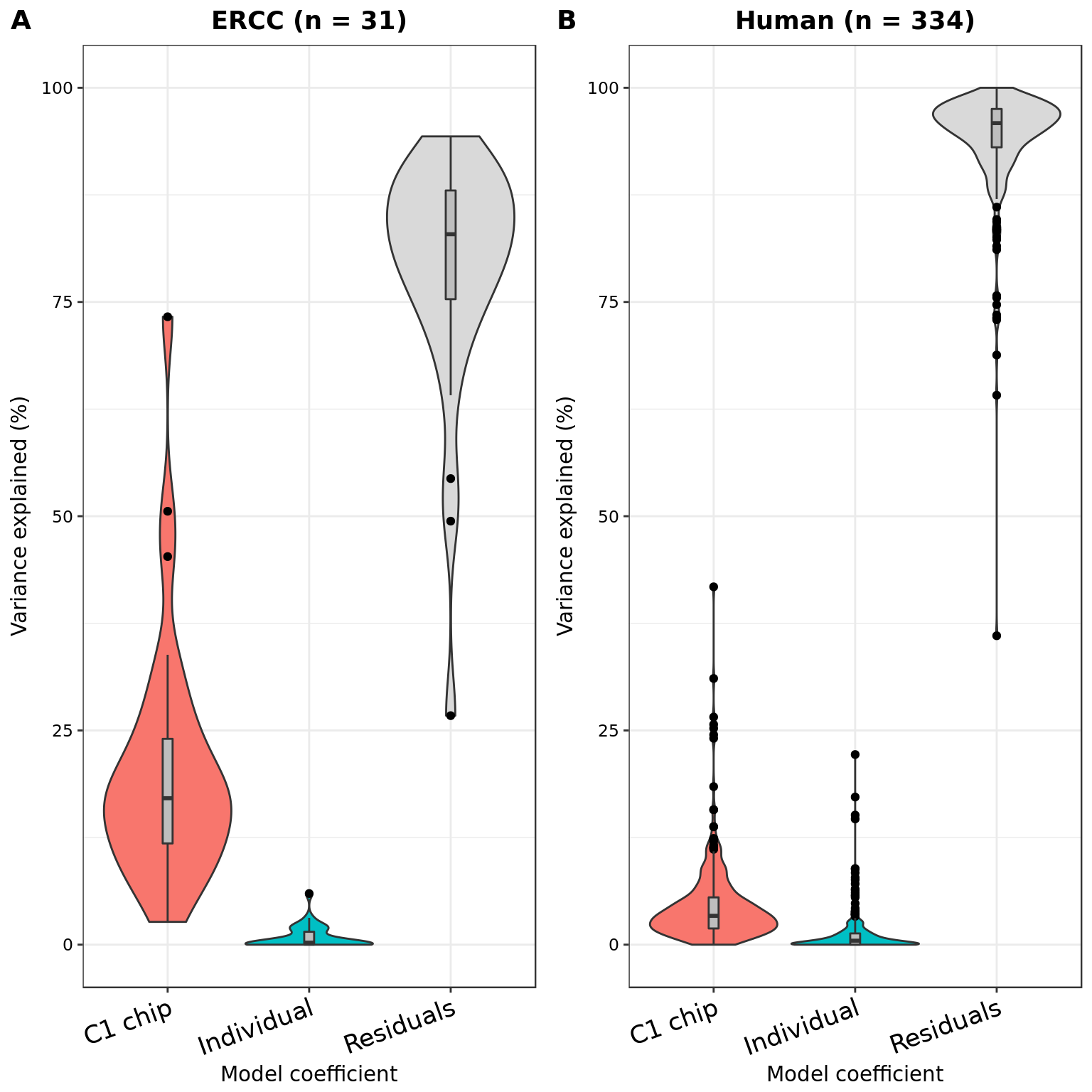
Session information
sessionInfo()R version 3.4.1 (2017-06-30)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Scientific Linux 7.2 (Nitrogen)
Matrix products: default
BLAS: /project2/gilad/jdblischak/miniconda3/envs/scqtl/lib/R/lib/libRblas.so
LAPACK: /project2/gilad/jdblischak/miniconda3/envs/scqtl/lib/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] parallel methods stats graphics grDevices utils datasets
[8] base
other attached packages:
[1] doParallel_1.0.10 iterators_1.0.8
[3] variancePartition_1.4.2 Biobase_2.38.0
[5] BiocGenerics_0.24.0 foreach_1.4.3
[7] edgeR_3.20.1 limma_3.34.1
[9] cowplot_0.9.1 ggplot2_2.2.1
loaded via a namespace (and not attached):
[1] Rcpp_0.12.13 nloptr_1.0.4 compiler_3.4.1
[4] git2r_0.19.0 plyr_1.8.4 bitops_1.0-6
[7] tools_3.4.1 lme4_1.1-13 digest_0.6.12
[10] nlme_3.1-131 evaluate_0.10.1 tibble_1.3.3
[13] gtable_0.2.0 lattice_0.20-34 rlang_0.1.2
[16] Matrix_1.2-7.1 yaml_2.1.14 stringr_1.2.0
[19] knitr_1.16 caTools_1.17.1 gtools_3.5.0
[22] locfit_1.5-9.1 rprojroot_1.2 grid_3.4.1
[25] rmarkdown_1.6 minqa_1.2.4 gdata_2.17.0
[28] reshape2_1.4.2 magrittr_1.5 MASS_7.3-45
[31] splines_3.4.1 backports_1.0.5 scales_0.5.0
[34] colorRamps_2.3 gplots_3.0.1 codetools_0.2-15
[37] htmltools_0.3.6 pbkrtest_0.4-7 colorspace_1.3-2
[40] labeling_0.3 KernSmooth_2.23-15 stringi_1.1.2
[43] lazyeval_0.2.0 munsell_0.4.3 This R Markdown site was created with workflowr